NutriScore Visualisation
Beverages products analysis
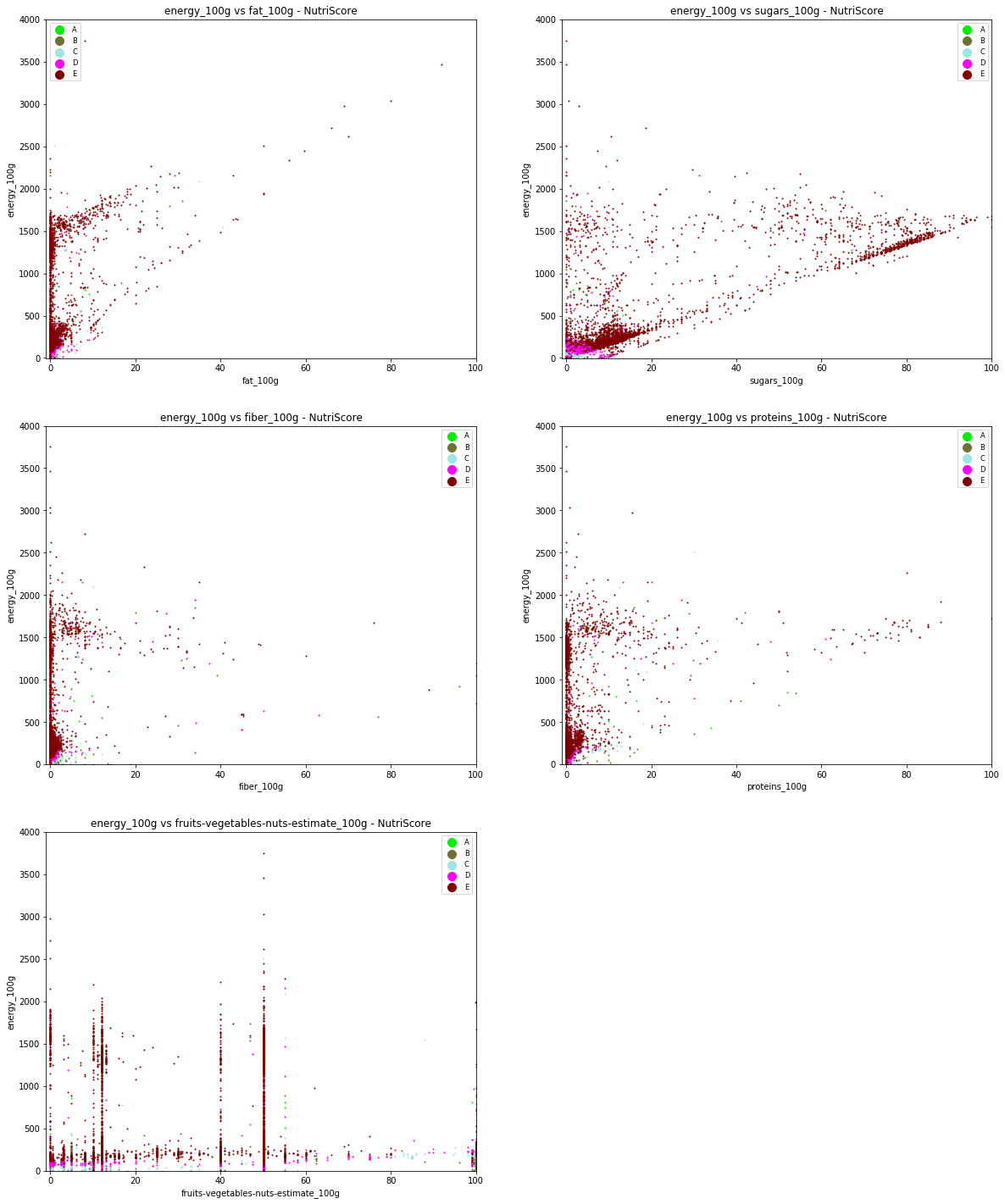
Here, one can see the scatter plot for product that will be considered as beverages by the NutriScore algorithm. One can observe that most of beverages have low-level of fats but are more sparse concerning sugars and proteins. One can see that the product graded E (worst grade) have the largest value in terms of energy, sugars and proteins and frequently contain less than 50% of fruits/vegetables/nuts. The differences between the other grades (A, B, C & D) are less noticeable. If we had to separate them using machine learning techniques, it would have been difficult. This is why we preferred to directly develop a calculation algorithm based on the official Nutri-Score computation rules.
Non-beverages products analysis
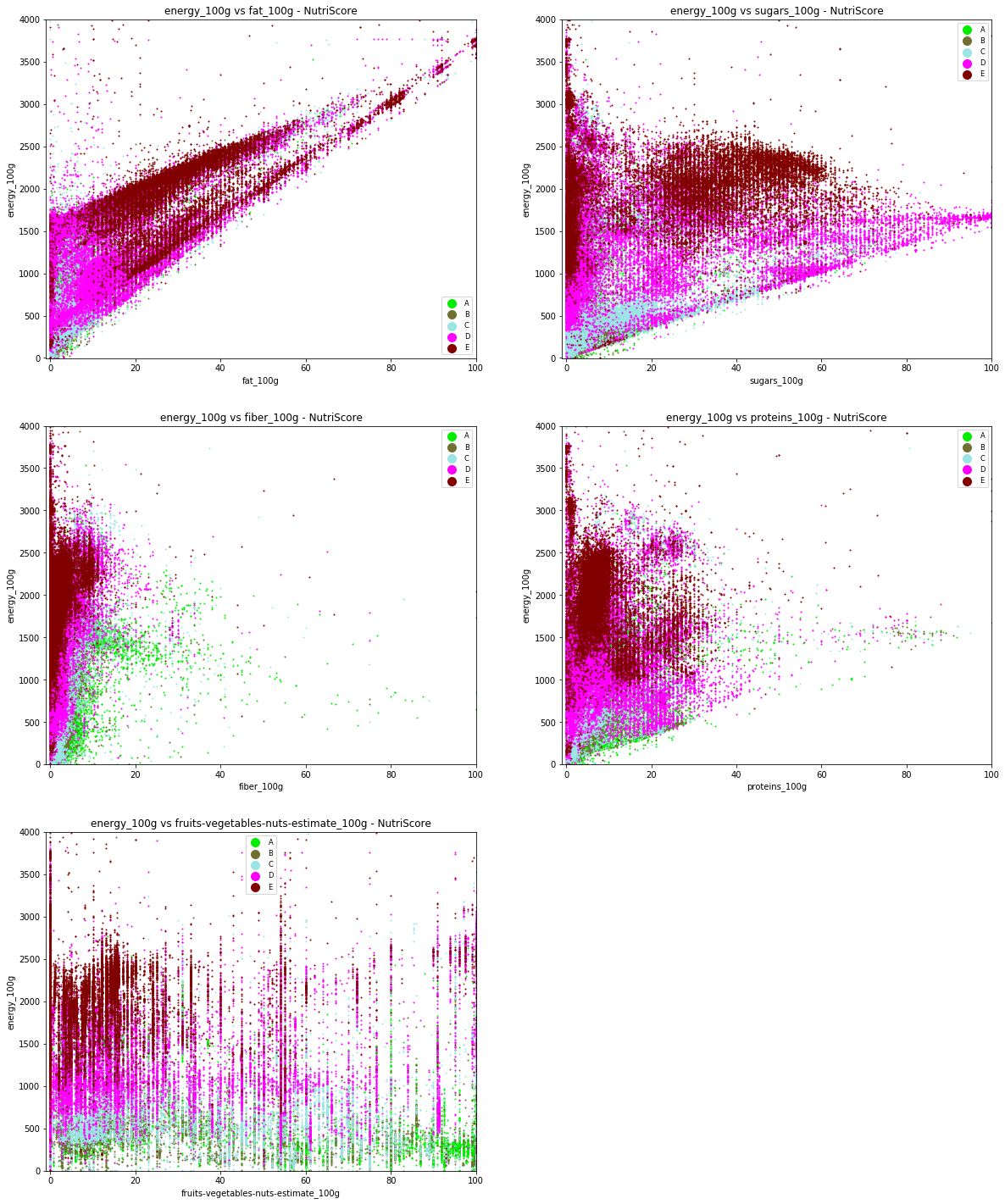
One can observe that the products graded C/D/E have very similar properties. They show a large scale of values for what concerns fats and sugars. But one should note, looking at the fruits/veg/nuts content vs energy plot, that it is possible to differentiate the grades according to their energy content, as one can observe several layers. Grade A have a larger amount of fiber, which seems to make sense, as fiber give negative points for the Nutri-Score (NB : the lower the NutriScore, the better the grade).
NutriScore - Computation
As stated above, we developped our NutriScore computation algorithm using the exact criteria specified in the official documents from the french Ministry of Agriculture. As the products effective grade are indicated in the database, we can quantify the accuracy of the algorithm and try to increase its efficiency.
In general, except for exceptions, the score is computed in this manner :
ScoreBeverages = Energy + Sugar - Fruits
ScoreNonBeverages = NegativePoints - PositivePoints = (Energy + Fat + Sugar + Sodium) - (Fruits + Fibers + Proteins)
For beverages grades:
Water ==> A
ScoreBeverages <= 1 ==> B
1 < ScoreBeverages <= 5 ==> C
5 < ScoreBeverages <= 9 ==> D
9 < ScoreBeverages <= 20 ==> E
For non-beverages grades:
ScoreNonBeverages < 0 ==> A
0 < ScoreNonBeverages <= 2 ==> B
2 < ScoreNonBeverages <= 10 ==> C
10 < ScoreNonBeverages <= 18 ==> D
18 < ScoreNonBeverages <= 40 ==> E
83.72 % of product in our final database have NutriScore provided by OpenFoodFacts
| a | b | c | d | e | Error | |
|---|---|---|---|---|---|---|
| a | 18314 | 849 | 81 | 11 | 10 | 80 |
| b | 2916 | 15828 | 671 | 57 | 65 | 306 |
| c | 1001 | 2981 | 24035 | 822 | 149 | 305 |
| d | 185 | 319 | 6855 | 32902 | 353 | 498 |
| e | 9 | 72 | 959 | 3387 | 26687 | 330 |
| Error | 0 | 0 | 0 | 0 | 0 | 0 |
The columns indicate the predicted grade and the rows the true grade.
For Beverages :
The accuracy according to the grade is 87.33 %, the accuracy according to the score is 54.05 %.
The fact that the score accuracy is much lower than the grade accuracy might be explained by the way our algorithm compute the grade for water. Only mineral waters can have the grade A, and all mineral waters have this grade. As a consequence, our algorithm focuses on the tags and not on the score computation.
For non-Beverages :
The accuracy according to the grade is 83.02 %, the accuracy according to the score is 58.40 %.
One can note the very high accuracy for beverages and non-beverages according to the grade. The algorithm raises low amount of errors that are due to missing values. Moreover, one can estimate that some information entered in the database is still inaccurate, even if we tried to complete and to correct it.
We also discovered some absurdities in the calculation of NutriScore by Openfoodfacts. For instance, in the case of chocolate milk drink powders, the rating is done as a solid, because chocolate is a powder, but the information on which Openfoodfact’s Nutriscore is based is the information of the diluted powder. Thus, powdered chocolate has the double advantage of being considered as a solid, but of having its diluted values used. This results in an A or B grade, which is ridiculous given the nutritional value of chocolate milk drinks.
What is more, the fruits/vegetables/nuts estimation is difficult to handle with, as there is absolutely no defined convention. Most of this classification has to be done manually when the product is entered in the database.